
At the heart of every scientific inquiry lies a fundamental dance between cause and effect, a relationship meticulously charted through the lens of dependent and independent variables. These two pillars form the bedrock of experimental design, guiding researchers through the complexities of observation, manipulation, and ultimately, understanding. From the intricate workings of the human mind to the vastness of the cosmos, the ability to discern and dissect these variables is paramount to unlocking the secrets of the world around us. This is where the story begins.
This article delves into the core distinctions between dependent and independent variables, illuminating their roles within controlled experiments across diverse fields. We’ll explore how researchers identify and manipulate independent variables, measure the responses of dependent variables, and account for the influence of control variables to ensure the integrity of their findings. Moreover, we will address the critical difference between correlation and causation, equipping you with the tools to navigate the often-misleading landscape of data interpretation. Finally, we’ll examine real-world applications and common pitfalls, offering practical insights for anyone seeking to unravel the mysteries of cause and effect.
Understanding the Fundamental Differences Between Dependent and Independent Variables in Scientific Investigations

The cornerstone of any scientific investigation rests on a clear understanding of variables. Specifically, distinguishing between dependent and independent variables is crucial for designing experiments, analyzing data, and drawing meaningful conclusions. This distinction dictates how an experiment is structured and how results are interpreted. Misidentifying these variables can lead to flawed experiments and incorrect conclusions, undermining the entire research process.
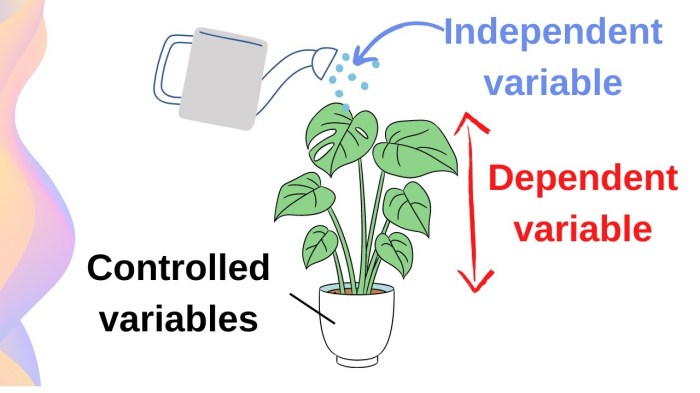
The core distinction between dependent and independent variables lies in their roles within an experiment. The independent variable is the factor that the researcher deliberately manipulates or changes. It’s the “cause” in the cause-and-effect relationship the experiment seeks to investigate. The dependent variable, on the other hand, is the factor that is measured or observed to see how it responds to changes in the independent variable. It’s the “effect” that the researcher is trying to understand. The independent variable is controlled by the experimenter, while the dependent variable is expected to change in response to that control. A well-designed experiment isolates the independent variable to determine its impact on the dependent variable, minimizing the influence of other factors (extraneous variables). This controlled environment allows researchers to establish a clear relationship between the variables and make valid inferences about cause and effect.
Illustrating Variable Functionality in Controlled Experiments
The interaction between independent and dependent variables is best understood through examples of controlled experiments. These examples illustrate how the independent variable is manipulated, and the dependent variable is measured to reveal their relationship.
* Scenario 1: Plant Growth and Sunlight. An experiment investigates the effect of sunlight on plant growth. The independent variable is the amount of sunlight the plants receive (e.g., hours of sunlight per day), which the researcher controls by placing plants in different locations or using artificial light sources. The dependent variable is the plant’s growth, measured by its height (in centimeters) or its biomass (in grams) after a set period.
* Scenario 2: Drug Dosage and Blood Pressure. A clinical trial examines the impact of a new drug on blood pressure. The independent variable is the dosage of the drug administered to the patients, which the researcher varies (e.g., 0mg, 50mg, 100mg). The dependent variable is the patient’s blood pressure, measured in millimeters of mercury (mmHg) at regular intervals.
* Scenario 3: Fertilizer Type and Crop Yield. A farmer wants to determine the best type of fertilizer for their crop. The independent variable is the type of fertilizer used (e.g., Fertilizer A, Fertilizer B, Fertilizer C). The dependent variable is the crop yield, measured by the weight of the harvested crop (e.g., kilograms per hectare).
* Scenario 4: Temperature and Reaction Rate. A chemist studies the effect of temperature on the rate of a chemical reaction. The independent variable is the temperature of the reaction (e.g., 25°C, 35°C, 45°C), which the chemist controls using a heating or cooling system. The dependent variable is the reaction rate, measured by the time it takes for a specific amount of reactant to be consumed or product to be formed.
* Scenario 5: Exercise and Heart Rate. A researcher explores the impact of exercise intensity on heart rate. The independent variable is the intensity of the exercise (e.g., walking, jogging, running). The dependent variable is the participant’s heart rate, measured in beats per minute (BPM) during and after the exercise.
Correctly identifying the independent and dependent variables is paramount for the validity of any research. Without this distinction, researchers risk misinterpreting their data and drawing incorrect conclusions about the relationships between factors. For instance, in a plant growth experiment, if the researcher believes plant height influences sunlight (which is incorrect), they may erroneously conclude that taller plants require more sunlight, failing to understand the causal relationship. Accurate identification ensures the experiment is properly designed, the data is correctly analyzed, and the findings accurately reflect the investigated phenomenon.
Identifying Independent Variables and Their Manipulation within Diverse Research Contexts
The cornerstone of any robust scientific investigation lies in the precise identification and manipulation of independent variables. These variables, the presumed causes, are systematically altered by researchers to observe their impact on dependent variables, the presumed effects. This process is crucial across various disciplines, enabling researchers to establish cause-and-effect relationships and draw meaningful conclusions. Identifying the independent variable, however, isn’t always straightforward and requires a nuanced understanding of the research question and the context within which it’s being explored. The methods used to pinpoint and control these variables vary depending on the field of study, the nature of the phenomenon being investigated, and the ethical considerations that must be taken into account.
Methods for Identifying Independent Variables
Researchers employ a variety of methods to identify independent variables, depending on the field of study. These methods range from observational techniques to controlled experiments.
In psychology, researchers often utilize experimental designs where participants are randomly assigned to different groups. For instance, in a study investigating the effects of a new therapy on depression, the independent variable might be the type of therapy received (e.g., cognitive behavioral therapy versus a control group receiving no therapy or a placebo). Researchers meticulously design the study to control for other factors that could influence the outcome. Methods include:
* Literature Reviews: Comprehensive reviews of existing research help identify potential independent variables. For example, if researching the effects of sleep deprivation on cognitive function, previous studies would highlight sleep duration as a key independent variable.
* Pilot Studies: Small-scale preliminary studies are used to test the feasibility of manipulating an independent variable and to refine research protocols. These studies may help to identify any unexpected challenges in the manipulation process.
* Surveys and Questionnaires: Surveys can be used to gather data on potential independent variables, such as demographic factors or lifestyle choices, which can then be correlated with dependent variables.
* Focus Groups: Discussions with a group of individuals can generate insights into potential independent variables, especially in qualitative research.
In economics, independent variables often relate to policy interventions, market conditions, or economic indicators. For example, a study examining the impact of a tax cut on consumer spending would identify the tax cut as the independent variable. Methods include:
* Econometric Modeling: Statistical techniques are used to analyze the relationships between economic variables, identifying those that influence others. For example, a regression analysis could identify the impact of interest rates (independent variable) on investment (dependent variable).
* Natural Experiments: Researchers observe the effects of naturally occurring events or policy changes that serve as independent variables. A classic example is analyzing the effects of minimum wage increases (independent variable) on employment rates (dependent variable).
* Simulations: Computer models are used to simulate economic scenarios, allowing researchers to manipulate independent variables and observe their effects.
In environmental science, independent variables might include factors such as pollution levels, climate change indicators, or the introduction of new species. Methods include:
* Field Studies: Researchers collect data in natural environments, often manipulating environmental conditions to observe their effects. For example, studying the impact of fertilizer application (independent variable) on plant growth (dependent variable).
* Laboratory Experiments: Controlled experiments are conducted to isolate and manipulate specific environmental factors.
* Remote Sensing: Satellites and other technologies are used to monitor environmental variables over large areas, allowing researchers to track changes and identify potential independent variables.
| Research Area | Independent Variable | Method of Manipulation | Example Study |
|---|---|---|---|
| Psychology | Type of Therapy (CBT vs. Placebo) | Random Assignment to Treatment Groups | A study examining the effectiveness of Cognitive Behavioral Therapy (CBT) for treating anxiety. Participants are randomly assigned to receive either CBT or a placebo treatment, and their anxiety levels (dependent variable) are measured. |
| Economics | Interest Rate | Analyzing historical data and econometric models | Analyzing the effect of changes in interest rates on consumer spending. A study uses historical interest rate data to predict the impact on the dependent variable, consumer spending. |
| Environmental Science | Fertilizer Application (Amount) | Controlled application of varying amounts of fertilizer to experimental plots | Investigating the impact of different levels of fertilizer on crop yield. Researchers apply varying amounts of fertilizer to different plots of land and measure the resulting crop yield (dependent variable). |
| Sociology | Exposure to Violence (Media) | Randomly showing different media to different groups | Researchers randomly assign participants to watch violent or non-violent media and then measure their aggression levels (dependent variable). |
The ability to control the independent variable is critical for isolating its effect on the dependent variable. This control is achieved through experimental design, random assignment, and the careful monitoring of extraneous variables that could confound the results. For example, in a pharmaceutical study, the dosage of a drug (independent variable) must be precisely controlled to assess its efficacy. Furthermore, ethical considerations are paramount. Researchers must ensure that any manipulation of independent variables does not pose undue risks to participants. This includes obtaining informed consent, minimizing potential harm, and protecting the privacy of participants. For instance, in a study involving exposure to stressful stimuli, researchers must ensure that the stress levels remain within acceptable ethical limits and that participants are fully informed about the potential risks.
Exploring Dependent Variables and Measuring Their Responses to Changes in Independent Variables
The accurate measurement of dependent variables is crucial for establishing cause-and-effect relationships in scientific research. Dependent variables, by definition, are the factors that are observed and measured to assess the impact of changes in the independent variables. The methods employed to quantify these responses vary widely across scientific disciplines, each presenting its own set of challenges and requiring careful consideration to ensure the validity and reliability of the findings.
Methods for Measuring Dependent Variables
Quantifying the responses of dependent variables requires the selection of appropriate measurement techniques that align with the specific research question and the nature of the variable being studied. These techniques can range from direct physical measurements to complex analytical procedures, and their selection is dictated by the nature of the dependent variable.
- Physical Measurements: In physics and engineering, dependent variables might be measured directly using calibrated instruments. For instance, in an experiment investigating the effect of temperature on the volume of a gas (Boyle’s Law), the volume would be the dependent variable, measured using a graduated cylinder or a similar device. The accuracy depends on the instrument’s calibration and the precision of the observer.
- Chemical Analyses: Chemistry often employs analytical techniques to measure dependent variables related to concentrations or reaction rates. For example, in a study examining the effect of a catalyst on a reaction rate, the concentration of a product (the dependent variable) might be measured using spectrophotometry, which determines the absorbance of light by the solution. This allows the quantification of how much product is present.
- Biological Assays: In biology and medicine, dependent variables are frequently assessed through biological assays. For instance, the effect of a drug on blood pressure (the dependent variable) could be measured using a sphygmomanometer. Another example is measuring the growth of bacteria in response to an antibiotic. The dependent variable, bacterial growth, is measured using techniques such as colony counting or optical density measurements.
- Psychological Assessments: In psychology, dependent variables often involve subjective measures, such as responses to questionnaires or reaction times. A study investigating the effect of sleep deprivation on cognitive performance might measure reaction time to a task as the dependent variable. The response time is quantified using specialized software.
- Economic Indicators: In economics, dependent variables might include inflation rates, unemployment rates, or GDP growth. These are typically measured using statistical methods based on data collected from various sources, such as surveys, government reports, and market analyses. These are often used to gauge the impact of fiscal policy on the economy.
Challenges and Mitigation of Bias in Measurement
The process of measuring dependent variables is susceptible to various sources of bias that can compromise the accuracy and validity of research findings. These biases can arise from the measurement instrument itself, the researcher’s expectations, or the participants in the study.
- Instrumental Bias: Measurement instruments may have inherent limitations or calibration errors that can lead to systematic errors in the data. Regularly calibrating instruments and using appropriate control measures can minimize this.
- Observer Bias: The researcher’s expectations can unconsciously influence the way they interpret or record data. For example, in a drug trial, researchers may unconsciously interpret symptoms differently depending on whether the participant is in the treatment or placebo group.
- Participant Bias: Participants may alter their behavior because they know they are being observed (the Hawthorne effect) or may try to provide answers they believe the researcher wants to hear (social desirability bias).
To mitigate these biases, researchers employ several strategies:
- Standardization: Standardizing measurement protocols, including instrument calibration, data collection procedures, and participant instructions, ensures consistency and reduces variability.
- Blinding: In studies involving human subjects, blinding, where either the participants (single-blind) or both the participants and the researchers (double-blind) are unaware of the treatment assignments, can minimize observer bias.
- Randomization: Randomly assigning participants to different treatment groups helps to ensure that any systematic differences between the groups are due to chance rather than bias.
- Control Groups: Including control groups (e.g., a placebo group) allows researchers to compare the effects of the independent variable against a baseline, helping to isolate the true impact of the independent variable.
- Data Validation: Implementing data validation checks, such as cross-referencing data from multiple sources or using statistical analyses to identify outliers, can improve data accuracy.
For example, in a clinical trial assessing the effectiveness of a new medication, a double-blind, placebo-controlled design is essential. Participants are randomly assigned to either the treatment group (receiving the medication) or the placebo group (receiving an inactive substance). Neither the participants nor the researchers know who is receiving which treatment until the end of the study. This approach minimizes both observer bias and participant bias, ensuring that any observed differences in the dependent variable (e.g., symptom severity) are due to the medication and not other factors.
The Role of Control Variables in Maintaining Experimental Integrity When Analyzing Relationships
In scientific investigations, establishing clear cause-and-effect relationships is paramount. While independent variables are manipulated and dependent variables are measured, the influence of extraneous factors can cloud the results. This is where control variables become critical, ensuring that observed changes in the dependent variable are genuinely due to the independent variable and not other, unintended influences.
The Purpose of Control Variables and Their Impact on Validity
Control variables are the elements in an experiment that are kept constant or consistent throughout the study. Their primary purpose is to minimize the impact of external factors that could potentially influence the dependent variable, thus distorting the relationship between the independent and dependent variables. By holding these factors constant, researchers can isolate the effect of the independent variable, making the results more reliable and valid.
The impact of effective control variables on the validity of experimental results is substantial:
- Enhanced Internal Validity: Control variables reduce the risk of confounding variables, which are factors that correlate with both the independent and dependent variables, potentially leading to spurious correlations. For example, if a study investigates the effect of a new fertilizer on plant growth, controlling for sunlight exposure, water intake, and soil composition ensures that any observed differences in plant growth are due to the fertilizer and not these other factors.
- Increased Accuracy: By minimizing the influence of extraneous factors, control variables allow for more precise measurement of the effect of the independent variable. This leads to more accurate data and more reliable conclusions.
- Strengthened Causal Inference: When control variables are properly implemented, researchers can more confidently infer a causal relationship between the independent and dependent variables. This is because alternative explanations for the observed changes in the dependent variable are effectively ruled out.
- Improved Replicability: Controlling for key variables makes it easier for other researchers to replicate the experiment and verify the findings. This is a cornerstone of the scientific method, as it helps to build confidence in the validity of the results.
Comparing and Contrasting Control and Independent Variables
The roles of control and independent variables are distinct yet intertwined in experimental design. Understanding their differences is crucial for conducting sound research.
- Independent Variables: These are the variables that the researcher actively manipulates or changes to observe their effect on the dependent variable. They are the “cause” in the cause-and-effect relationship. For example, in a study on the effect of a new drug, the dosage of the drug is the independent variable.
- Control Variables: These are the variables that are kept constant or consistent throughout the experiment. They are not the focus of the study but are controlled to prevent them from influencing the results. In the drug study example, control variables might include the age and health status of the participants, the timing of drug administration, and the environment in which the participants are observed.
In essence, the independent variable is the focus of the investigation, while control variables serve to create a stable baseline against which the effects of the independent variable can be measured. Without effective control variables, the impact of the independent variable can be obscured by the influence of uncontrolled factors, making it difficult to draw valid conclusions.
Implementing Control Variables in a Hypothetical Experiment
A researcher wants to investigate the effect of different types of music on test performance. The independent variable is the type of music (classical, pop, and no music). The dependent variable is the test score. To ensure accuracy, the researcher implements several control variables:
- Test Difficulty: The same standardized test is used for all participants.
- Testing Environment: All participants take the test in the same quiet room, free from distractions.
- Time of Day: All participants take the test at the same time of day to control for potential variations in alertness.
- Prior Knowledge: Participants are screened to ensure they have a similar level of prior knowledge related to the test subject.
By controlling these variables, the researcher can confidently attribute any differences in test scores to the type of music, rather than other factors like test difficulty, environment, or prior knowledge. If the researcher found that the participants listening to classical music performed significantly better than the others, they could then draw a more reliable conclusion about the relationship between music and test performance. This also means that, when a person is planning to take an exam, it is useful to listen to classical music before the exam.
Causation versus Correlation
Understanding the relationship between variables is fundamental to scientific inquiry. While analyzing data, it’s crucial to differentiate between correlation and causation. Correlation indicates a statistical relationship between two variables, suggesting they tend to move together. Causation, however, implies that a change in one variable directly causes a change in another. This distinction is critical for accurate data interpretation and drawing valid conclusions. Mistaking correlation for causation can lead to flawed decision-making and incorrect predictions.
Differentiating Correlation and Causation
The core difference lies in the nature of the relationship. Correlation describes the degree to which two variables are associated. It doesn’t necessarily mean one causes the other. Causation, on the other hand, implies a direct cause-and-effect relationship. Establishing causation requires rigorous evidence demonstrating that changes in the independent variable directly lead to changes in the dependent variable.
For instance, consider the observation that ice cream sales and the number of reported shark attacks increase during the summer months. These variables are likely *correlated* – both increase simultaneously. However, this correlation doesn’t mean that eating ice cream *causes* shark attacks, or vice versa. The underlying factor driving both is warmer weather, leading to more people swimming (and potentially encountering sharks) and increased ice cream consumption. This is a classic example of a lurking or confounding variable.
The key to distinguishing between correlation and causation lies in the experimental design. A well-designed experiment manipulates the independent variable and measures its effect on the dependent variable, while controlling for other factors. This allows researchers to isolate the effect of the independent variable and establish a causal relationship. Correlation can be measured using statistical techniques like Pearson’s correlation coefficient, which ranges from -1 to +1, with values closer to -1 or +1 indicating stronger relationships. However, these techniques alone cannot prove causation.
Scenarios Where Correlation Does Not Imply Causation
Many real-world examples illustrate the fallacy of assuming causation from correlation. Recognizing these scenarios is crucial for critical thinking.
- Spurious Correlation: This occurs when two variables appear to be related, but the relationship is due to a third, unobserved variable. For example, a study might find a correlation between the number of storks nesting in a village and the birth rate in that village. It’s tempting to conclude that storks bring babies, but the real explanation is that both are influenced by factors like rural living and a healthier environment.
- Reverse Causation: Sometimes, the direction of the causal relationship is misinterpreted. For instance, a study might find a correlation between stress levels and caffeine consumption. It might be tempting to conclude that caffeine causes stress. However, it’s also possible that stressed individuals consume more caffeine to cope, making the relationship reverse.
- Coincidence: Occasionally, two variables might correlate simply by chance. Over a large dataset, some random correlations are bound to appear. For example, a website might track the number of people using a specific search term and the number of people wearing a certain type of hat. A small correlation might appear by chance and should not be considered meaningful.
Rigorous experimental design helps avoid these pitfalls. This includes:
- Random Assignment: Participants should be randomly assigned to different groups (e.g., treatment and control groups) to minimize bias.
- Control Groups: A control group that does not receive the treatment (manipulation of the independent variable) is crucial for comparison.
- Blinding: Minimizing bias by ensuring participants and, ideally, researchers, are unaware of who receives the treatment. This is often double-blind, where neither the participants nor the researchers know who is receiving the treatment.
- Replication: Repeating the experiment multiple times to confirm the results and reduce the likelihood of chance findings.
Statistical Techniques for Establishing Causation
While correlation can be measured using various statistical techniques, establishing causation requires more sophisticated methods. These methods often focus on isolating the effect of the independent variable.
- Regression Analysis: This technique models the relationship between a dependent variable and one or more independent variables. It can estimate the magnitude and direction of the effect of each independent variable on the dependent variable, controlling for other variables. Multiple regression allows researchers to assess the independent contribution of each variable while holding others constant. For example, a regression model might be used to examine the effect of advertising spending (independent variable) on sales (dependent variable), controlling for factors like price and competitor activity.
- Intervention Analysis: This approach involves analyzing data before and after an intervention or treatment. By comparing the changes in the dependent variable before and after the intervention, researchers can assess the causal effect. For example, if a company introduces a new marketing campaign (intervention) and sales increase, intervention analysis can help determine if the campaign caused the increase.
- Propensity Score Matching: This technique is used when researchers cannot randomly assign participants to different groups. It involves matching individuals with similar characteristics based on their “propensity score” (the probability of receiving the treatment). This helps to create comparable groups and reduce bias.
- Instrumental Variables: This method uses a variable (the instrument) that is correlated with the independent variable but not directly related to the dependent variable, except through the independent variable. This allows researchers to estimate the causal effect of the independent variable while addressing endogeneity issues.
Interpreting the data from these techniques requires careful consideration. A statistically significant result (e.g., a p-value less than 0.05) suggests that the observed effect is unlikely to be due to chance. However, it doesn’t automatically prove causation. Researchers must also consider the experimental design, the plausibility of the causal mechanism, and the consistency of the findings across multiple studies. It’s crucial to note that the strength of the evidence for causation depends on the quality of the data, the rigor of the analysis, and the context of the research. For example, the effect of a new drug on a disease would require rigorous clinical trials. These trials involve a control group, random assignment, and often blinding to reduce bias and provide the strongest evidence for causation.
Practical Applications
Understanding dependent and independent variables isn’t just an academic exercise; it’s a critical skill applicable to solving real-world problems across diverse fields. From healthcare to business, the ability to identify, manipulate, and analyze these variables empowers individuals and organizations to make data-driven decisions, improve outcomes, and gain a competitive edge. This section will delve into how these concepts can be applied practically, providing detailed examples and a step-by-step approach to illustrate their utility.
Applying Variable Concepts to Real-World Problems
The core principle is to dissect complex problems into manageable components. Identifying the independent variable, the factor being manipulated or changed, and the dependent variable, the outcome being measured, allows for a structured approach to problem-solving. This framework provides clarity, enabling informed decisions and strategic planning.
Let’s consider two examples:
In healthcare, a pharmaceutical company is testing a new drug to treat high blood pressure.
* The independent variable is the dosage of the new drug (e.g., 5mg, 10mg, 20mg). This is what the researchers are deliberately changing.
* The dependent variable is the patient’s blood pressure, measured in systolic and diastolic readings. This is the outcome that the researchers are measuring to see if it changes in response to the drug.
* Control variables would include the patient’s age, gender, pre-existing conditions, and lifestyle factors. These are kept constant to ensure that any changes in blood pressure are due to the drug, and not to other factors.
In business, a marketing team wants to determine the effectiveness of a new advertising campaign.
* The independent variable is the advertising spend (e.g., $10,000, $20,000, $30,000). This is the amount of money the team is investing in advertising.
* The dependent variable is the sales revenue generated. This is the outcome that the marketing team is measuring to see if it increases in response to the advertising spend.
* Control variables could include the product’s price, the competitor’s actions, and the overall economic climate. These are kept as constant as possible to isolate the effect of the advertising campaign on sales.
These examples highlight the universality of these concepts.
Step-by-Step Approach to Case Study Analysis
Analyzing a case study requires a systematic approach. Here’s a step-by-step guide:
1. Define the Problem: Clearly articulate the issue or challenge presented in the case study. What is the organization or individual trying to achieve or overcome?
2. Identify the Independent Variable(s): Determine the factor(s) that are being manipulated or changed in the case. These are the drivers of the situation. Look for actions, interventions, or changes introduced.
3. Identify the Dependent Variable(s): Pinpoint the outcome(s) that are being measured or observed. What results are being sought or assessed? These are the effects or consequences of the independent variables.
4. Identify the Control Variables: Determine what factors are being held constant or controlled to isolate the relationship between the independent and dependent variables. What aspects of the situation are not changing?
5. Analyze the Relationship: Evaluate the relationship between the independent and dependent variables. Does a change in the independent variable lead to a change in the dependent variable? What is the nature of this relationship (positive, negative, or no correlation)?
6. Draw Conclusions and Make Recommendations: Based on the analysis, draw conclusions about the effectiveness of the intervention or the factors influencing the outcome. Formulate recommendations for future actions or decisions.
For instance, consider a case study about a retail company experiencing declining sales.
1. Problem: Declining sales revenue.
2. Independent Variable: The implementation of a new customer loyalty program.
3. Dependent Variable: Sales revenue.
4. Control Variables: Marketing spending, product pricing, and the number of customers.
5. Analysis: The company tracks sales before and after the program’s launch, assessing the correlation. If sales increase after the program’s implementation, it suggests a positive relationship.
6. Conclusions/Recommendations: If the relationship is positive, the program is effective. Recommendations could involve expanding the program or adjusting its features.
Informed Decision-Making and Critical Thinking
A solid understanding of dependent and independent variables is a cornerstone of critical thinking. It allows for a more objective and analytical approach to problem-solving, moving beyond assumptions and gut feelings. By systematically examining cause-and-effect relationships, individuals can evaluate information more effectively, identify biases, and make informed decisions. This analytical skill is essential in various contexts, from personal finance to professional settings, enabling individuals to navigate complex situations with greater clarity and confidence. The ability to differentiate between what is being changed and what is being measured fosters a deeper understanding of the world around us and empowers us to make evidence-based decisions.
Common Misconceptions and Errors in Variable Identification and Application
Accurately identifying and differentiating between dependent and independent variables is fundamental to the design and interpretation of any research study. Errors in this process can lead to incorrect conclusions, wasted resources, and ultimately, a flawed understanding of the phenomenon under investigation. This section explores common pitfalls in variable identification and offers strategies to avoid them.
Misidentifying the Independent Variable
The independent variable, the presumed cause, is often the source of confusion. Several misconceptions contribute to this error.
- Assuming Causation from Correlation: A common mistake is inferring a causal relationship solely from a correlation. For example, a study might observe a positive correlation between ice cream sales and crime rates. Misinterpreting this could lead to the incorrect conclusion that ice cream consumption causes crime. The independent variable, in this case, might be overlooked. The real independent variable could be a confounding factor, such as warmer weather, which drives both ice cream sales and increased outdoor activity (and potentially, a slight rise in certain types of crime).
- Reversing the Variables: Researchers sometimes mistakenly assign the dependent variable as the independent variable. Consider a study investigating the impact of different teaching methods (independent variable) on student test scores (dependent variable). A researcher might incorrectly define test scores as the independent variable and teaching methods as the dependent variable, leading to a flawed understanding of the relationship.
- Failing to Recognize Multiple Independent Variables: Complex research often involves multiple independent variables. Ignoring or oversimplifying these can obscure the true nature of the relationships. A study on the effectiveness of a new drug might have several independent variables, including dosage, frequency of administration, and patient demographics. Failing to account for all of these can make it difficult to isolate the effect of the drug itself.
- Treating Confounding Variables as Independent Variables: Confounding variables are factors that influence both the independent and dependent variables, potentially distorting the observed relationship. Treating a confounding variable, such as socioeconomic status in a study on education, as an independent variable, without controlling for its effect, can lead to inaccurate results. For instance, in a study examining the impact of parental involvement (independent variable) on children’s academic achievement (dependent variable), socioeconomic status could be a confounding variable. Children from higher socioeconomic backgrounds might benefit from more parental involvement and have better academic outcomes, regardless of the involvement level.
Misidentifying the Dependent Variable
The dependent variable, the presumed effect, is also prone to misidentification. Errors here can significantly impact the interpretation of results.
- Using Proxies Instead of Direct Measures: Researchers may use proxy variables, which are indirect measures, instead of directly measuring the dependent variable. For example, instead of measuring actual job performance (dependent variable), a researcher might use employee self-reported satisfaction (proxy). While self-reported satisfaction might be correlated with performance, it is not a direct measure and can introduce bias.
- Choosing Inappropriate Scales or Metrics: The choice of measurement scale can dramatically influence the results. Using a nominal scale to measure a variable that is inherently continuous, or vice versa, can obscure meaningful relationships. For example, measuring patient recovery time (dependent variable) using a simple “yes/no” scale (nominal) would provide far less detailed information than measuring it in days (ratio scale).
- Failing to Account for Measurement Error: All measurements contain some degree of error. Ignoring or underestimating measurement error can lead to inaccurate conclusions about the relationship between variables. In a study measuring the effectiveness of a new exercise program (independent variable) on weight loss (dependent variable), if the scale used to measure weight is inaccurate, the results will be unreliable.
- Ignoring the Time Element: The dependent variable’s measurement needs to align with the independent variable’s influence. For instance, if a researcher is studying the impact of a new advertising campaign (independent variable) on sales (dependent variable), measuring sales immediately after the campaign might not capture the full effect. Some time might be needed for the advertising to influence consumer behavior.
Strategies for Avoiding Errors
To ensure accuracy in variable identification, researchers should adopt several strategies.
- Clearly Define Research Questions and Hypotheses: A well-defined research question is the foundation of any study. It helps clarify the relationship between variables and guides the selection of independent and dependent variables.
- Conduct a Thorough Literature Review: Understanding previous research in the field can provide insights into established relationships between variables and help avoid common pitfalls.
- Use a Conceptual Framework: Developing a conceptual framework that visually represents the relationships between variables can help clarify the roles of independent and dependent variables.
- Pilot Test Measurements: Before collecting data, pilot-testing measurement instruments can help identify and correct any issues with the scales or metrics used.
- Statistical Analysis for Control: Employing appropriate statistical techniques to control for confounding variables is crucial for isolating the effect of the independent variable on the dependent variable.
- Seek Peer Review: Having the research design and methodology reviewed by peers can help identify potential errors in variable identification.
Final Thoughts
In conclusion, the mastery of dependent and independent variables is not merely an academic exercise; it’s a gateway to critical thinking and informed decision-making. By understanding the interplay of these fundamental elements, we empower ourselves to dissect complex problems, evaluate evidence with greater precision, and ultimately, contribute to a more nuanced and accurate understanding of the world. The journey through this landscape of research provides a powerful lens through which to view information, making us better informed and more insightful individuals. The knowledge gained here is the first step in the journey of true understanding.
{kind=link}